On parle de statistiques à deux dimensions lorsqu'on étudie conjointement deux variables aléatoires, X et Y. On ne cherche plus à caractériser la distribution de chacune des variables, ce qui est du ressort des statistiques à une dimension, mais bien à caractériser leur distribution conjointe.
On se pose donc la question de savoir si la distribution d'une des variables influence ou non celle de l'autre.
Un exemple classique vous est donné à l'illustration ci-dessous: l'envergure et le poids de chauves-souris sont-ils distribués de manière dépendante ou indépendante l'un de l'autre ?
Une chauve-souris a-t-elle forcément un poids important lorsqu'elle a une grande envergure ?
Une chauve-souris a-t-elle forcément une grande envergure lorsqu'elle a un poids important ?
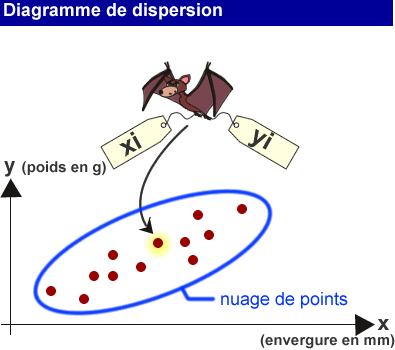
Les statistiques à deux dimensions s'appliquent non plus aux valeurs de X et Y considérées de manière individuelle, mais bien aux couples (X;Y), qui représentent les deux mesures qui ont été réalisées sur un même individu.
Dans notre exemple, pour chaque chauve-souris, un couple (envergure; poids) a été mesuré.
L'ensemble de ces points est reporté sur un graphique à deux dimensions, afin d'estimer graphiquement la dispersion de ces données.
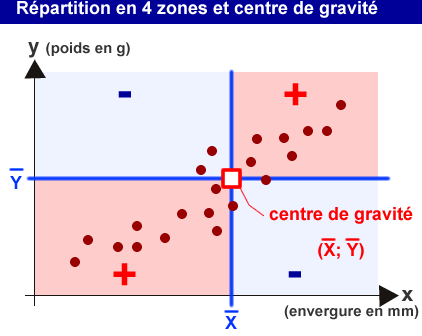
Le centre de gravité du nuage de points est un point fictif qui a pour coordonnées (moyenne des X; moyenne des Y).
Pour chaque point, on peut quantifier son écart par rapport à ce centre de gravité en réalisant le calcul du produit des écarts:
PE=(Xi-Mx).(Yi-My)
Ce produit des écarts est positif pour les points situés dans les quadrants roses du graphique ci-dessus, et négatif s'ils sont situés dans les quadrants bleus. Le nuage de points schématisé dans le graphique ci-dessus a donc des PE majoritairement positifs.
En réalisant la somme de tous ces PE, je peux donc avoir une estimation de l'orientation du nuage de points par rapport à son centre de gravité.
SPE : Somme des Produits des Ecarts
Si la SPE est positive, comme c'est le cas ici, le nuage de points est orienté de manière ascendante dans le sens gauche-droite. Si la SPE du nuage de points est négative, c'est qu'il est orienté de manière descendante.
La SPE amène donc énormément d'informations sur le sens de la relation qui pourrait éventuellement exister entre X et Y.
Note: Dans certaines situations
expérimentales il peut être intéressant de comparer des nuages de points provenant d'expériences différentes. Dans ce cas, on doit ramener les deux nuages de points dans une échelle comparable. Pour cela on réalise une réduction des variables X et Y respectives, selon les formules suivantes:
Xr�duit=(Xi-Mx)/Sx
Yr�duit=(Yi.-My)/Sy
Le processus de réduction s'opère en retirant des coordonnées en X et en Y leur moyenne respective. Cela permet de repositionner les deux centres de gravité aux coordonnées identiques de (0;0).
Pour éliminer la variabilité propre au contexte expérimental, les différences entre coordonnées (X ou Y) expérimentales et moyennes (de X ou de Y) sont divisées par l'écart-type (de X ou de Y). Par définition, comme les centres de gravité sont aux coordonnées (0;0), la somme des valeurs réduites est nulle.
A partir de la SPE calculée précédemment, il est possible de quantifier et de caractériser la relation existant entre X et Y gr�ce au coefficient de corrélation (r).
Coefficient de corr�lation: r
Le coefficient de corrélation (noté r) quantifie l'intensité et le sens de la relation qui existe entre deux variables.
Si les deux variables varient
indépendamment l'une de l'autre, sa valeur est de 0. Si les deux variables évoluent
parallèlement (Y augmente lorsque X augmente), sa valeur sera positive, avec un maximum de 1 (lorsque l'évolution de Y est directement proportionnelle à celle de x). Si les deux variables évoluent à l'inverse l'une de l'autre, sa valeur sera négative, avec un minimum de -1.
Donc: -1 r 1
Cependant, le coefficient de corrélation entre X et Y dépend tout autant de la pente du nuage de points que de leur alignement.
Le coefficient de corrélation est calculé à partir de la covariance, ou variance commune à X et à Y, qui est calculée selon la formule suivante :
Covariance= Sxy = SPE/n
La covariance est donc le PE moyen du nuage de points. Elle est positive lorsque le nuage de points a une orientation ascendante, et négative lorsque ce nuage a une orientation descendante.
A partir de la covariance, on peut déduire le coefficient de corrélation:
Coefficient de
corrélation = r = Sxy/Sx.Sy
Si une relation
suffisamment
importante se confirme entre X et Y, on peut poursuivre l'analyse en effectuant une régression.
Une régression est l'estimation de l'équation de la relation existant entre les variables X et Y.
Régression linéaire :
Cette relation peut être linéaire ou non. Dans le cas du modèle linéaire l'équation de la régression est:
Modèle linéaire: Y=a+bX.
Les paramètres a (ordonnée à l'origine) et b (pente) peuvent être déterminés selon deux méthodes, la méthode des moindres carrés, ou celle des moindres rectangles, qui seront choisies en fonction du type de relation existant entre X et Y. Ces deux méthodes seront détaillées à la page suivante.
Lors de l'établissement d'une équation de régression, le coefficient de détermination (R²) détermine à quel point l'équation de régression est adaptée pour décrire la distribution des points.
Si le R² est nul, cela signifie que l'équation de la droite de régression détermine 0% de la distribution des points. Cela signifie que le modèle mathématique utilisé n'explique absolument pas la distribution des points.
Si le R² vaut 1, cela signifie que l'équation de la droite de régression est capable de déterminer 100% de la distribution des points. Cela signifie que le modèle mathématique utilisé, ainsi que les paramètres a et b calculés sont ceux qui déterminent la distribution des points.
Cela se traduit de manière graphique selon la relation suivante: plus le coefficient de détermination se rapproche de 0, plus le nuage de points est diffus autour de la droite de régression. Au contraire, plus le R² tend vers 1, plus le nuage de points se rapproche de la droite de régression. Quand les points sont exactement alignés sur la droite de régression, R²=1.
Donc: 0 R²1
Le R² est calculé selon la formule:
R² = SCEy estimés par l'équation de régression /SCEtotale
R²= variabilité expliquée par la régression / variabilité totale.
En fin de module, vous trouverez une animation devant vous permettre, nous l'espérons, de mieux saisir les subtilités relatives au R², mais aussi au r.
NOTE: le R² n'est le carré du r que dans le cas particulier de la régression linéaire. Dans les autres régressions (logarithmique, exponentielle, puissance, etc.) ce n'est pas le cas. C'est pour éviter cette confusion facile qu'on note habituellement le r du coefficient de corrélation en minuscule, et celui du coefficient de détermination en majuscule.
La détermination de la pente (b) et de l'ordonnée à l'origine (a) peut se faire selon deux méthodes différentes.
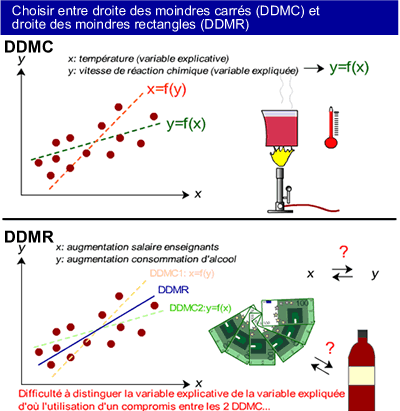
On utilise la méthode des moindres carrés lorsqu'à priori une relation de cause à effet évidente relie X et Y (lorsque la valeur de X dépend de Y, ou lorsque la valeur de Y dépend de celle de X). On distingue alors la variable expliquée et la variable explicative.
exemple: C'est parce que la température augmente (X; variable explicative) que la vitesse de réaction chimique augmente (Y; variable expliquée), et non l'inverse.
On utilise celle des moindres rectangles lorsqu'aucune relation de cause à effet n'existe à priori de manière évidente entre X et Y.
Un des intérêts d'une régression est qu'avec les paramètres a et b on peut estimer des valeurs de Y pour des valeurs de X qu'on n'a pas pu mesurer (car cela coûte cher, ou que c'est difficile à réaliser...).
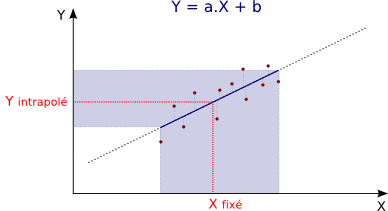
Cependant, la précision de cette estimation d'une valeur de Y varie fort selon qu'elle est estimée à partir d'un X compris dans l'intervalle des mesures initiales (intrapolation) ou si elle est estimée à partir d'un X situé à l'extérieur de cet intervalle (extrapolation).
Intrapolation :
Intrapolation = Evaluation d'une variable dans les limites de l'échantillon.
L'intrapolation de la valeur de y correspondant à une valeur mesurée de x
est d'autant plus fiable que l'équation de la droite a été établie avec un R² proche de 1.
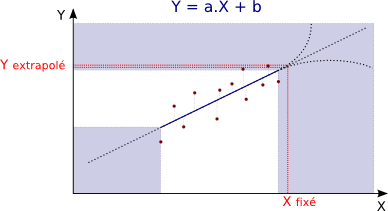
Extrapolation :
Extrapolation = Evaluation d'une variable hors des limites de l'échantillon.
Extrapolation pertinente :
L'extrapolation est d'autant plus pertinente qu'elle est réalisée
près des limites de l'échantillon.
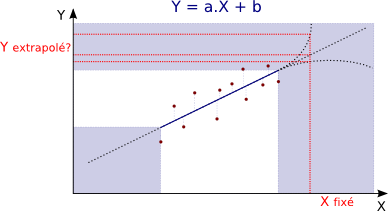
Extrapolation aberrante :
L'extrapolation est d'autant moins fiable qu'on est loin des limites de
l'échantillon car le modèle linéaire n'est plus forcément d'application.
Toutes les situations expérimentales ne se simplifient pas par une régression linéaire. Dans certains cas, il faut utiliser d'autres modèles pour décrire la relation existant entre X et Y.
Pour déterminer les paramètres de telles régressions, on transforme les valeurs de X et/ou Y pour retrouver le modèle linéaire.
Voici quelques modèles de régressions non-linéaires, et leurs transformations respectives :
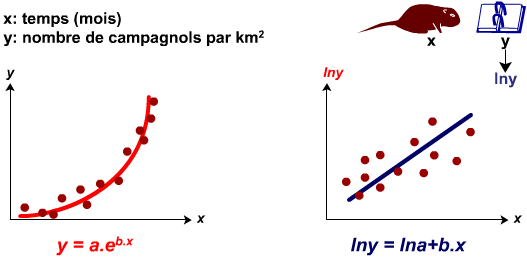
Modèle exponentiel: Y=a.ebx
Le modèle exponentiel se linéarise en calculant le logarithme népérien de y.
Exemple : Analyse de la croissance du nombre de campagnols par km carré en fonction du temps.
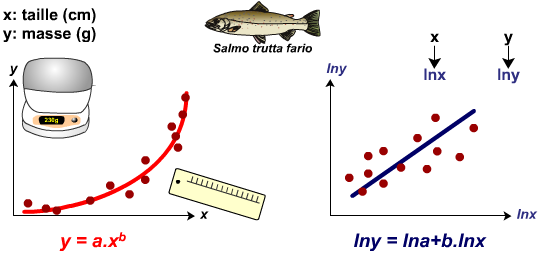
Modèle puissance: Y=a.xb
Le modèle puissance se linéarise en calculant les logarithmes népériens de x et y.
Exemple : étude de la relation entre la taille et la masse de truites Farios.
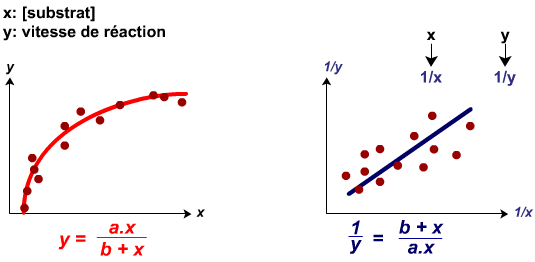
Modèle double inverse: Y=(a.x)/(b+x)
Le modèle double inverse se linéarise en calculant les inverses de x et y : 1/x et 1/y.
Exemple : analyse de la relation entre la concentration en substrat et la vitesse de réaction d'une enzyme.
Lorsque l'animation commence, les points sont alignés horizontalement. Le r et le R² sont indéterminables car inexistants dans ce type de situation.
Si à partir de cette situation rectiligne vous ordonnez une rotation du nuage de points, le r et le R² prennent une valeur de 1 (ou -1 pour le r selon le sens de rotation), car les points restent parfaitement alignés, et que la pente est non nulle.
En modifiant individuellement la position des points, on peut constater que le r et le R² dépendent aussi bien de l'inclinaison du nuage de points que du rapprochement des points avec la droite de régression.
En
déplaçant horizontalement ou verticalement ce nuage de points, le r et le R² ne sont pas modifiés, car ils tiennent compte des écarts entre les points (via la SPE), et non des valeurs absolues des coordonnées (X;Y).
Modèle exponentiel:
Dans ce modèle, le R² n'est plus le carré du r et ces deux
paramètres n'évoluent plus forcément de manière
parallèle. Le r est plus dépendant de l'inclinaison du nuage, et le R² de la capacité de l'équation de régression à déterminer la distribution des points.
Note: Une notion non vue au cours (et donc non matière d'examen) est ajoutée à cette simulation. Il s'agit du leverage, que vous pouvez afficher en cliquant sur la petite case dans le coin inférieur droit. Le leverage mesure l’influence potentielle d’un point sur la droite. Il est calculé pour chaque point à partir des valeurs de X seulement, selon la formule:
Pour chaque point, le leverage varie de 1/n à 1. Les points très éloignés de la moyenne ont un plus grand leverage: ils ont plus de poids sur la détermination des paramètres a et b de la régression que ceux qui sont proches de la moyenne.
Dans l'animation, les cercles bleus ont un rayon proportionnel à 2000 fois la valeur de leur leverage, afin de les rendre visibles.
Vous remarquerez que lorsqu'il y a deux points (le nombre de points peut se modifier dans le petit cadre: on peut faire afficher de 2 à 9 points), les deux leverages sont égaux. Pour bien saisir le mode de variation d'un leverage, nous vous conseillons une simulation à 3 points.