imprimer
Module 230:
La régression multiple est la suite logique de la régression simple vue lors des statistiques descriptives à deux dimensions et dans l'ANOVA1.
Le but de la régression multiple est de déterminer le modèle mathématique permettant d’expliquer au mieux la variabilité d’une variable Y en fonction, non plus de une, mais de plusieurs variables X1, X2, X3 etc...
Exemple: expliquer la variabilité de la taille de truites adultes (Y) en fonction de la température des bassins d'élevage (X1), du pH de l'eau (X2), de la teneur en protéines de leurs aliments (X3), etc... le tout simultanément.
Tout comme pour la régression simple, il existe plusieurs modèles de régressions multiples:
Le modèle linéaire est une équation qui oriente une droite dans un hyper-espace qui a autant de dimensions qu'il y a de variables ( Y, X1, X2, X3 = 4 dimensions). C'est le modèle de régression multiple le plus simple :
Y = B0 + B1X1 + B2X2 + B3X3 + ...
Le terme B0 est l'ordonnée à l'origine, c'est-à-dire la valeur de Y lorsque toutes les variables Xi sont nulles.
Les modèles non-linéaires (exponentiels, logarithmiques, etc...) sont très complexes, et sortent du cadre de ce cours. Ils ne seront donc pas abordés.
Cas particulier :
Le modèle polynomial est un modèle de régression simple car il ne concerne que deux variables (X et Y) mais qui sera néanmoins détaillé ici car son mode de calcul est similaire à celui de la régression multiple.
Le modèle polynomial ne concerne qu'une seule variable X, mais qui sera élevé à plusieurs puissances croissantes. Cette équation permet de tracer une courbe qui aura autant de points d’inflexion qu’il y a de degrés au polynôme :
Y = B0 + B1X + B2X2 + B3X3 + ....
Le but de la régression simple est de déterminer le modèle mathématique qui permet d'expliquer au mieux la variabilité d'une variable Y en fonction d'une variable X.
Exemple: expliquer la variabilité de la taille de truites adultes (Y) en fonction de la température des bassins d'élevage (X).
Pour bien conceptualiser la démarche effectuée lors de l'analyse de la régression, prenons le problème à l'envers, et tentons de comprendre quels sont les fondements théoriques de cette analyse.
Pour cela, partons du modèle linéaire et tentons d'expliquer la manière dont des points peuvent se distribuer expérimentalement.
| Rappel : Régression linéaire simple: Une variable aléatoire X. Modèle : Y=B0+B1X |
Le modèle idéal d'une régression linéaire simple est une droite dans un plan.
Prenons un exemple ou Y=2+0,6X. |
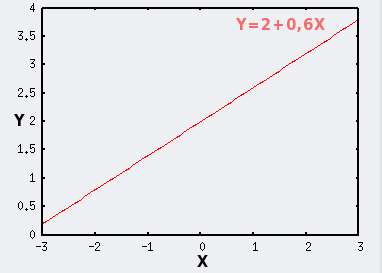 |
Lorsque X est une variable aléatoire normale, les points se projettent sur la trajectoire de la droite selon une distribution normale, et sont donc d'autant plus nombreux qu'on se rapproche du point dont les coordonnées sont (mX;mY).
La distribution des points sur la droite est donc influencée par le mode de distribution des X, c'est à dire par une variabilité de type horizontal.
Dans notre exemple X est une variable normale de paramètres μ=0 et σ=1.
Le point de coordonnées (mX;mY) est symbolisé par le gros point rouge.
|
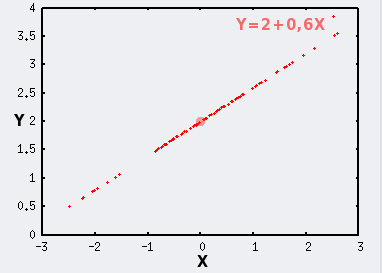 |
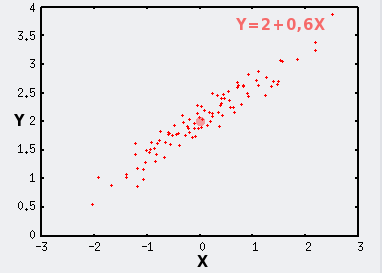
En conditions expérimentales, la distribution n'est jamais idéale. Des erreurs de mesures, des imprécisions, et des sources de variabilité d'origines diverses viennent s'ajouter au modèle normal. Dans ce cas les points ne se distribuent plus selon une droite parfaite, mais selon un nuage, d'autant plus proche de la droite parfaite que ces variabilités supplémentaires sont faibles.
Ces sources supplémentaires de variabilité, si X et Y sont mesurés, influencent la distribution des points horizontalement si elles s'appliquent à X, et verticalement si elles concernent Y.
Dans notre exemple, pour simplifier les choses, nous avons résumé ces sources de variabilité supplémentaires en une variable aléatoire qui disperse les points verticalement autour de la droite selon un modèle normal de paramètres ?=0 et ?=0,15.
Le point de coordonnées (mX;mY) est symbolisé par le gros point rouge.
|
 |
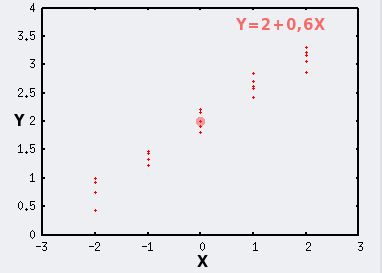
Lorsque la variable X est fixée, ici aux valeurs -2, -1, 0, 1 et 2, il n'y a plus de variabilité additionnelle sur X, et on visualise mieux la variabilité additionnelle qui ne concerne que Y, qui est toujours ici de paramètres μ=0 et σ=0,15.
Le point de coordonnées (mX;mY) est symbolisé par le gros point rouge.
|
 |
|
Le but de la régression est donc, face à une situation expérimentale, de chercher à quantifier ces sources de variabilités additionnelles verticales et horizontales, de manière à retrouver quel serait le modèle mathématique qui caractériserait au mieux la distribution des points si ces variabilités additionnelles, inévitables en conditions expérimentales, n'existaient pas.
|
Rappels :
Pour en savoir plus sur les modes de calculs de la pente et de l'ordonnée à l'origine :
Utilisons le même genre de démarche pour conceptualiser les fondements de la régression multiple, et détaillons les différents modes de régressions multiples linéaires.
Régression linéaire multiple à deux variables X
Prenons notre modèle de régression précédent (Y=2+0,6X) et rajoutons une variable aléatoire normale X2.
Le modèle devient donc par exemple: Y=2+0,6X1+1,2X2
| Rappel : Régression linéaire multiple à deux variables aléatoires: Modèle : Y=B0+B1X1+B2X2 |
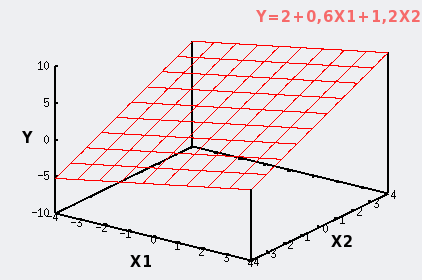
Le modèle idéal d'une régression linéaire multiple à deux variables X est un plan dans un espace à 3 dimensions (X1,X2,Y).
Prenons un exemple ou Y=2+0,6X1+1,2X2.
Ce modèle décrit la projection dans l'espace d'un plan défini par les deux droites d'équations :
Y=2+0,6X1 dans le référentiel (X1,Y).
Y=2+1,2X2 dans le référentiel (X2,Y). |
 |
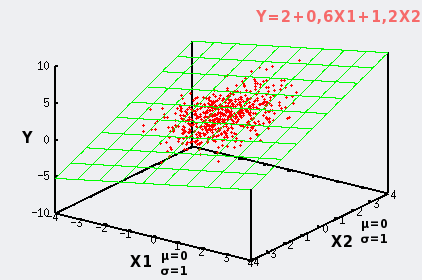
Lorsque X1 et X2 sont des variables aléatoires normales, les points se répartissent sur le plan selon l'intégration de deux distributions normales, et sont donc d'autant plus nombreux qu'on se rapproche du point dont les coordonnées sont (mX1;mX2;mY).
La distribution des points sur le plan est donc influencée par les paramètres de distribution des X1 et X2, c'est-à-dire par une variabilité horizontale à deux dimensions.
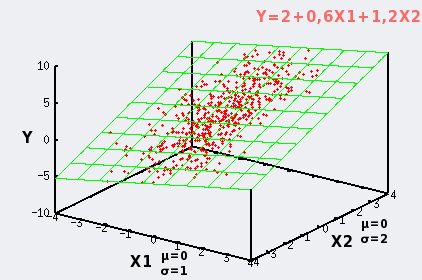
Dans notre premier exemple X1 et X2 sont des variables normales de paramètres μ=0 et σ=1. Dans ce cas le nuage de points est rond.
Dans notre second exemple X1 et X2 n'ont pas le même écart-type σ: Dans ce cas le nuage de points est de forme ovale. |
 |
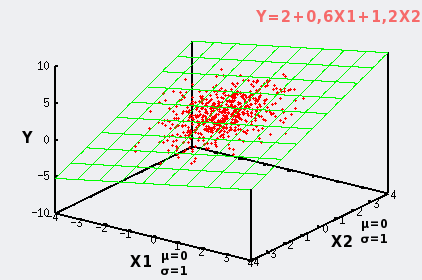
En conditions expérimentales, la distribution n'est jamais idéale. Des erreurs de mesures, des imprécisions, et des sources de variabilité d'origines diverses viennent s'ajouter au modèle normal. Dans ce cas les points ne se distribuent plus selon un plan parfait, mais selon un nuage, d'autant plus proche du plan parfait que ces variabilités supplémentaires sont faibles.
Ces sources supplémentaires de variabilité, si X1, X2, et Y sont mesurés, influencent la distribution des points horizontalement si elles s'appliquent à X1 et X2, et verticalement si elles concernent Y.
Dans notre exemple, pour simplifier les choses, nous avons résumé ces sources de variabilité supplémentaire en une variable aléatoire qui disperse les points verticalement par rapport au plan selon un modèle normal de paramètres μ=0 et σ=0,5.
Pour bien conceptualiser ceci en 3D le même nuage de points est illustré sous deux perspectives différentes, la seconde étant dans l'axe du plan du modèle idéal: on voit alors que les points ne sont plus uniquement dans le plan, mais se répartissent de part et d'autres pour former un nuage en 3D. |
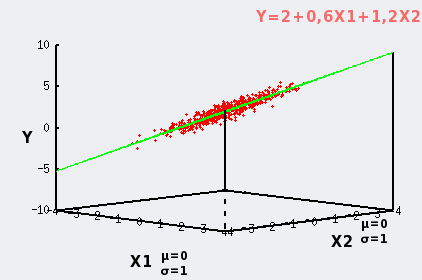 |
| Lorsque la variable X1 est fixée, ici aux valeurs -3, -2, -1, 0, 1, 2, et 3, le nuage de points se résume à des tranches de variabilité. . |
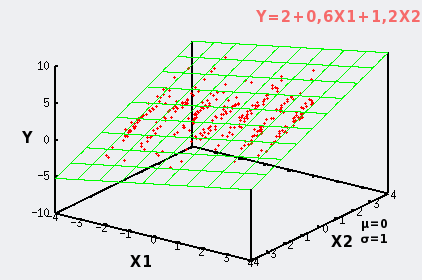 |
| Lorsque les deux variables X1 et X2 sont de valeurs fixées, le nuage de points se résume à des colonnes de variabilité. |
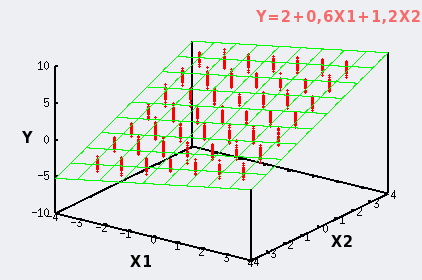 |
| Le but de la régression est donc, face à une situation expérimentale, de chercher à quantifier ces sources de variabilités additionnelles verticales et horizontales, de manière à retrouver quel serait le modèle mathématique qui caractériserait au mieux la distribution des points si ces variabilités additionnelles, inévitables en conditions expérimentales, n'existaient pas. |
Régression non-linéaire multiple à deux variables X
Dans la régression multiple le modèle est considéré comme non-linéaire à partir du moment où la distribution des points dans au moins une des dimensions ne suis pas un modèle linéaire
| Exemples de régressions multiples non-linéaires |
Les modèles non-linéaires étant fort nombreux nous nous contenterons ici de donner deux exemples de représentation graphique de cas de régression non-linéaire.
Premier exemple : la relation entre Y et X1 suit un modèle linéaire, celle entre Y et X2 un modèle logarithmique.
Y= 1+0,6X1 + log(X2).
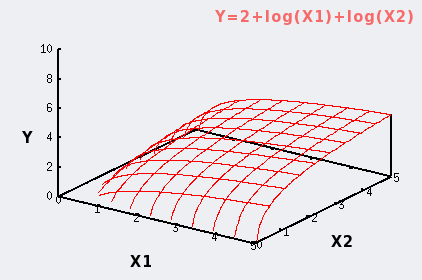
Deuxième exemple : les deux variables X ont une relation logarithmique avec Y.
Y= 1+log(X1) + log(X2). |
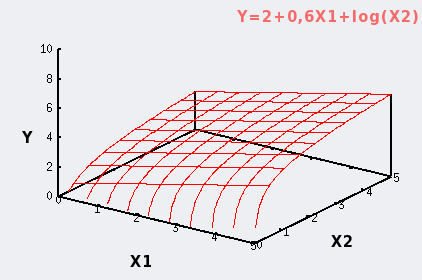
 |
Le critère qui permet de déterminer le meilleur jeu de valeurs pour les paramètres B0, B1, B2, B3 … est la maximisation du coefficient de détermination
R2 = Var(Ymodélisé)/ Var(Yobservé)
ou, ce qui revient au même, la minimisation globale des écarts entre les valeurs de Y modélisées et observées .
Le principe de la méthode consiste à développer l’équation de la somme des carrés des écarts entre les observations et le modèle, pour Y, (SCERy) et d’en calculer la dérivée partielle par rapport à chacun des paramètres. Le minimum de la fonction SCERy correspond au point où toutes les dérivées partielles sont nulles.
Ce système d’équation peut être résolu de façon analytique par le calcul matriciel suivant :
b = (X’X)-1X’Y
X est une matrice de genre n x p comprenant l’ensemble des n valeurs de X1, X2 … Xp-1. On ajoute à X une colonne constante ( Xp=1 partout) pour estimer le paramètre libre B0.
Y est un vecteur colonne n x 1 comprenant l’ensemble des n valeurs de Y
Le produit matriciel combine donc les genres suivants :
p x n ~ n x p ~ p x n ~ n x 1
Il est défini et produit le vecteur colonne b de genre p x 1, qui reprend la valeur des p paramètres B0, B1, B2, … Bp-1.
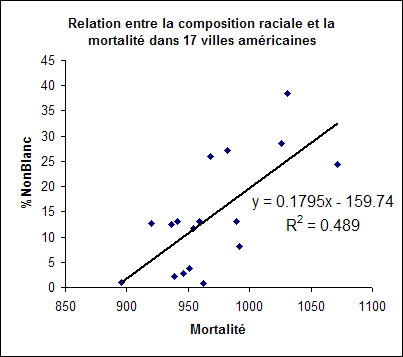
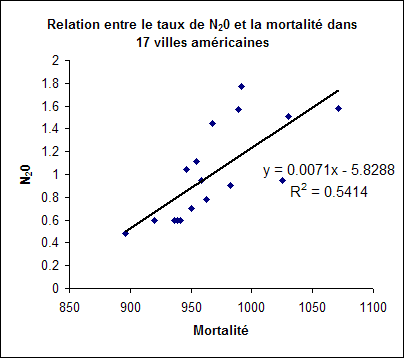
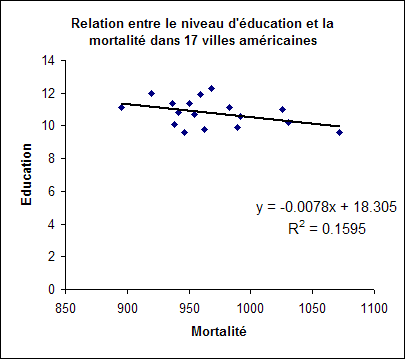
La mortalité, la composition raciale (% de non blancs), un polluant atmosphérique (protoxyde d’azote, N2O) et le niveau d’éducation ont été relevés dans quelques villes américaines (subset des données de http://lib.stat.cmu.edu/DASL/Datafiles/SMSA.html).
Ville USA |
Mortalité |
%NonBlanc |
N2O |
Education |
| |
Allentown, Bethlehem, PA-NJ |
962,35 |
0,80 |
0,78 |
9,8 |
Atlanta, GA |
982,29 |
27,10 |
0,90 |
11,1 |
Baltimore, MD |
1071,29 |
24,40 |
1,58 |
9,6 |
Birmingham, AL |
1030,38 |
38,50 |
1,51 |
10,2 |
Columbus, OH |
958,84 |
13,10 |
0,95 |
11,9 |
Flint, MI |
941,18 |
13,10 |
0,60 |
10,8 |
Dayton-Springfield, OH |
936,23 |
12,40 |
0,60 |
11,4 |
Kansas City, MO |
919,73 |
12,60 |
0,60 |
12 |
Louisville, KY-IN |
989,26 |
13,10 |
1,57 |
9,9 |
Pittsburgh, PA |
991,29 |
8,10 |
1,77 |
10,6 |
Providence, RI |
938,5 |
2,20 |
0,60 |
10,1 |
Richmond-Petersburg, VA |
1025,5 |
28,60 |
0,95 |
11 |
Syracuse, NY |
950,67 |
3,80 |
0,70 |
11,4 |
Washington, DC-MD-VA |
967,8 |
25,90 |
1,45 |
12,3 |
Reading, PA |
946,19 |
2,70 |
1,04 |
9,6 |
Worcester, MA |
895,7 |
1,00 |
0,48 |
11,1 |
Youngstown-Warren, OH |
954,44 |
11,70 |
1,11 |
10,7 |
L’analyse à deux variables produit les résultats suivants :
L’analyse en régression multiple se base sur les matrices suivantes :
Y |
|
|
X |
|
|
962,35 |
|
1 |
0,80 |
0,78 |
9,8 |
982,29 |
|
1 |
27,10 |
0,90 |
11,1 |
1071,29 |
|
1 |
24,40 |
1,58 |
9,6 |
1030,38 |
|
1 |
38,50 |
1,51 |
10,2 |
958,84 |
|
1 |
13,10 |
0,95 |
11,9 |
941,18 |
|
1 |
13,10 |
0,60 |
10,8 |
936,23 |
|
1 |
12,40 |
0,60 |
11,4 |
919,73 |
|
1 |
12,60 |
0,60 |
12 |
989,26 |
|
1 |
13,10 |
1,57 |
9,9 |
991,29 |
|
1 |
8,10 |
1,77 |
10,6 |
938,50 |
|
1 |
2,20 |
0,60 |
10,1 |
1025,50 |
|
1 |
28,60 |
0,95 |
11 |
950,67 |
|
1 |
3,80 |
0,70 |
11,4 |
967,80 |
|
1 |
25,90 |
1,45 |
12,3 |
946,19 |
|
1 |
2,70 |
1,04 |
9,6 |
895,70 |
|
1 |
1,00 |
0,48 |
11,1 |
954,44 |
|
1 |
11,70 |
1,11 |
10,7 |
Et produit le vecteur b calculé suivant:
b = (X’X)-1X’Y
par la fonction excel :
=PRODUITMAT(INVERSEMAT(PRODUITMAT(TRANSPOSE(X);X));PRODUITMAT(TRANSPOSE(X);Y))
b0 |
1109,57 |
b1 |
36,0395 |
b2 |
2,2969 |
b3 |
-19,456 |
Les valeurs prédites par le modèle sont calculées en appliquant l’équation:
Ymod = 1109,57 + 36,04 X1 + 2,29 X2 -19,45 X3
Y |
observé |
modélisé |
écarts |
| |
Allentown, Bethlehem, PA-NJ |
962,35 |
948,79 |
13,56 |
Atlanta, GA |
982,29 |
988,4 |
-6,11 |
Baltimore, MD |
1071,29 |
1035,77 |
35,52 |
Birmingham, AL |
1030,38 |
1053,8 |
-23,42 |
Columbus, OH |
958,84 |
942,53 |
16,31 |
Flint, MI |
941,18 |
951,23 |
-10,05 |
Dayton-Springfield, OH |
936,23 |
937,95 |
-1,72 |
Kansas City, MO |
919,73 |
926,74 |
-7,01 |
Louisville, KY-IN |
989,26 |
1003,56 |
-14,3 |
Pittsburgh, PA |
991,29 |
985,76 |
5,53 |
Providence, RI |
938,5 |
939,82 |
-1,32 |
Richmond-Petersburg, VA |
1025,5 |
995,64 |
29,86 |
Syracuse, NY |
950,67 |
921,69 |
28,98 |
Washington, DC-MD-VA |
967,8 |
981,91 |
-14,11 |
Reading, PA |
946,19 |
966,53 |
-20,34 |
Worcester, MA |
895,7 |
913,1 |
-17,4 |
Youngstown-Warren, OH |
954,44 |
968,41 |
-13,97 |
| |
Variance |
1893,44 |
= 1547,85 |
+ 345,59 |
|
|
|
|
R2 = |
1547,85 |
/ 1893,44 |
= 0,82 |
Soit une forte augmentation de la valeur prédictive pour la fonction des variables prises ensemble.
La question qui suit généralement l'approche par la régression multiple est de choisir parmi les variables X le plus petit nombre d'entre elles qui explique au mieux la variabilité de Y.
Une méthode courante est une régression itérative qui inclut d’abord dans le modèle la variable qui propose le meilleur coefficient de détermination. Ensuite, celle qui améliore le plus le coefficient de détermination et ainsi de suite.
Alternativement, toutes les variables sont entrées dans le modèle et les variables sont progressivement exclues, en fonction de celles qui contribuent le moins au modèle.
Il faut noter que la seconde variable qui entre dans le modèle n’est pas forcément celle qui présente, à elle seule, le second meilleur coefficient de détermination avec Y. Sinon, la solution serait triviale. En effet, X1 et X2 peuvent être très corrélées, voire quasi redondantes. Dans ce cas la qualité du modèle ne sera pas améliorée. C’est donc la variable qui contribue le plus à réduire la variabilité résiduelle, du modèle en voie d’élaboration qui sera sélectionnée à chaque étape.
La solution b = (X’X)-1X’Y est mise en pratique par le logiciel Excel pour la régression linéaire simple et la régression polynomiale.
X |
Y |
1 |
14,26 |
4 |
13,54 |
7 |
10,98 |
10 |
4,94 |
13 |
1,72 |
16 |
9,19 |
19 |
24,81 |
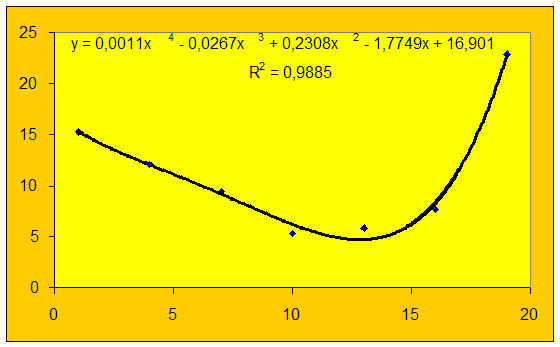
Exemple de régression polynomiale
(menu Graphique« Ajouter une courbe de tendance »)
Aucune solution n’est proposée pour le modèle linéaire multiple, mais le calcul se réalise facilement à l’aide des fonctions TRANSPOSE( ), PRODUITMAT( ) et INVERSEMAT( ).
Les modèles non-linéaires gérés par excel (logarithmique, exponentiel et puissance) sont calculés par la régression linéaire simple via la transformation de X et/ou de Y en log, la solution étant retransformée en anti-log.
Le logiciel Excel ne réalise pas de régression non linéaire proprement dite. Les fonctions sigmoïdes, multiples exponentielles, Michaëlis Menten … n’ont pas de solution analytique et doivent être réalisées par un logiciel qui propose un algorithme de minimisation numérique. A noter que même les fonctions linéarisables (exponentielle, puissance…) tirent avantage de cette approche.
Pour faire de l’inférence, notamment pour obtenir l’intervalle de confiance des paramètres, il est préférable d’utiliser un logiciel statistique plus sophistiqué que le tableur.
Les principes et les mises en garde concernant les limites de cette approche sont développés au module 20 dans le cadre de l’équation la plus simple Y = B0 + B1X1 . Ce sont les points spécifiques à la généralisation du modèle qui seront abordés ici.
Les précautions suivantes doivent être prises pour interpréter les résultats :
Plus on complexifie le modèle, plus la variabilité résiduelle peut être – apparemment- expliquée. Le nombre d’observations doit être relativement grand par rapport au nombre de variables incluses dans le modèle. Bien qu’il n’existe aucune règle absolue en cette matière on se référera au minimum à la règle empirique n > 2p
Les coefficients sont délicats à interpréter. En effet, B1 donne la variation de X1 correspondant à l’augmentation d’une unité de Y, pour autant que X2 reste constant. En pratique, cela est irréaliste car X1 est généralement corrélé à X2.
Les relations bivariées doivent préalablement être explorées graphiquement. La présence de données extrêmes ou aberrantes, la non linéarité de certaines relations, les écarts systématiques au modèle sont susceptibles d’affecter grandement les résultats.
Les conditions de linéarité étant souvent précaires et limitées à un domaine de X, l’extrapolation des résultats est toujours hasardeuse.
La régression polynomiale produit un modèle très « plastique » qui interpole bien les points mais ne possède aucune valeur d’extrapolation. La valeur des paramètres ne peut pas être associée à une explication structurelle du phénomène décrit.